
E2E ML Based Crypto Trading Algorithm
Infra
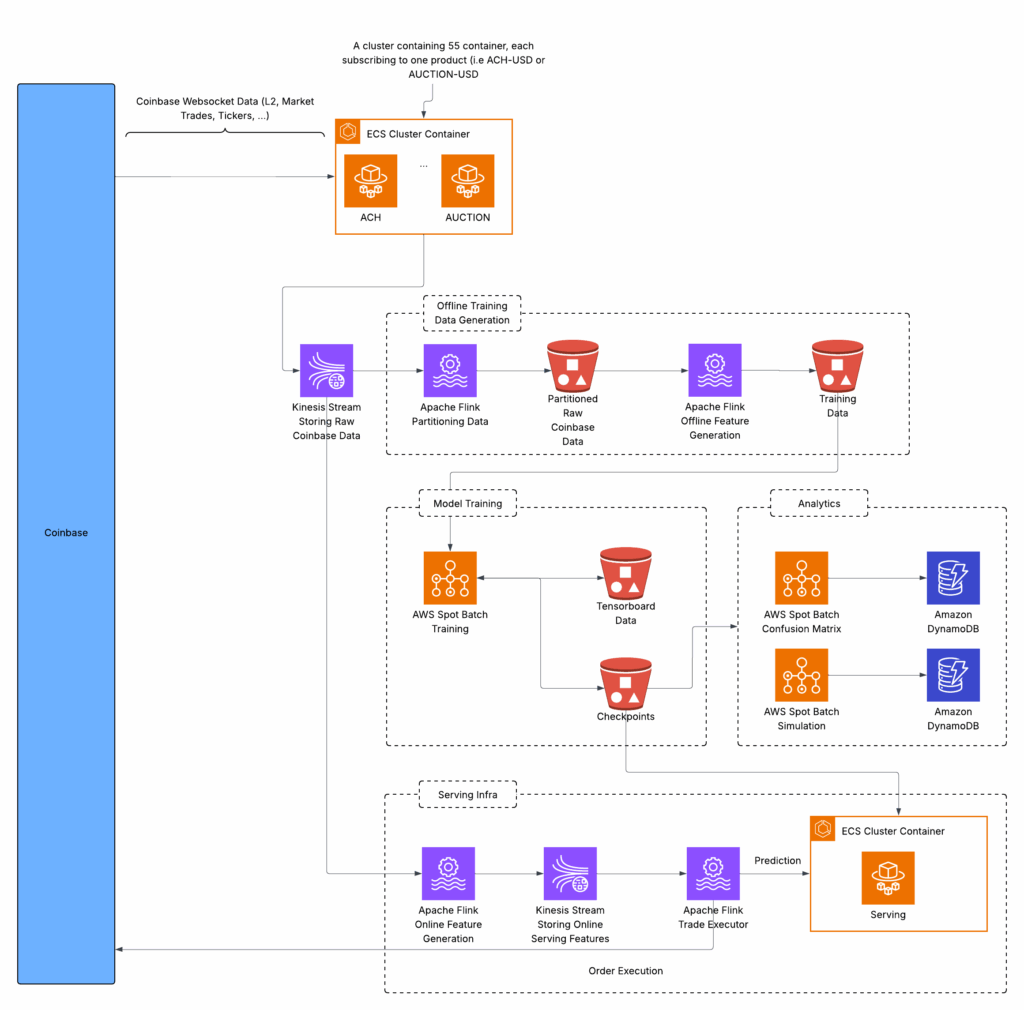
The e2e infrastructure was developed in AWS. The diagram below highlights the different services.
- Data Collection
-
-
- For every coin, Coinbase offers websockets users can subscribe to in order to obtain different set of real time data. An ECS cluster was set up, with each task subscribed to different channels associated with one product (i.e. coin).
- The tasks would submit data to a kinesis data stream. Two different flink applications would subscribe to this stream. One to generate offline training data and another to generate live features for serving
- Offline Training Data Generation:
- For offline training the flink application would read from the kinesis stream above and partition the data. Due to the stateful nature of the incoming data partitioning happens on a daily basis. The partition starts at the end of the previous partition and continues until the next day once a subsequent snapshot is received from Coinbase . The partitioned data is stored in an S3 bucket
- Another flink application with a parallelism > 1 will read from the partitioned data and generate training features + labels and output to the training data S3 bucket.
-
- Model Training:
-
-
- Model training occurs on AWS spot instances. Due to the pre-emptable nature of these instances a checkpoint and relevant tensorboard data is published after each epoch to an S3 bucket. After pre-emption the new instance will continue where the previous instances left off.
- Analytics:
- While metrics such as the model loss can be an indicator of how well the predictions are improving they don’t provide a way to understand how the prediction models will perform against the system goals. Other analytics tools were developed such as:
- Confusion Matrix: Runs on the evaluation dataset and prints out a confusion matrix of the predictions vs the optimal actions
- Simulation: Simulates the trade algorithm along with simulated USD and coin reserves and evaluates the profitability of the system
- While metrics such as the model loss can be an indicator of how well the predictions are improving they don’t provide a way to understand how the prediction models will perform against the system goals. Other analytics tools were developed such as:
-
- Serving:
-
- Apache flink application reads from the raw data kinesis stream and generates features. The features are sent to another kinesis stream
- A second apache flink application reads from the second kinesis stream and sends the features to the prediction model which is being served in an ECS cluster. After it receives predictions it will determine the optimal action and execute on it. The optimal action takes into into account existing buy/sell orders and the available reserves (coins, USD)
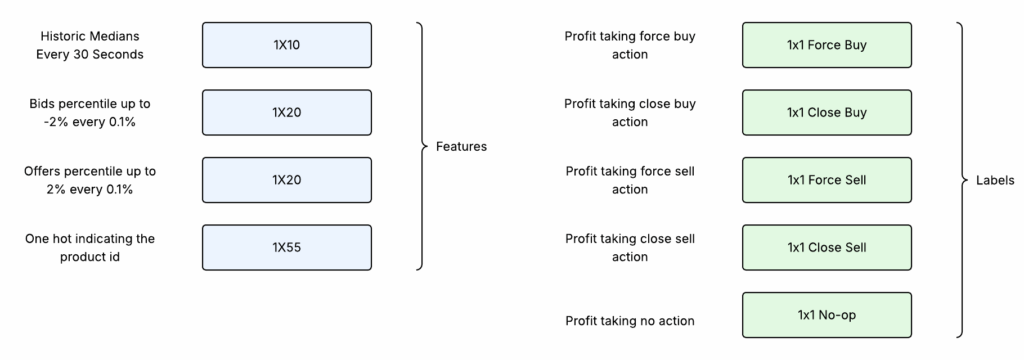
Features and Labels
The ML model would require 4 features as input and would generate 5 labels.
- Features
-
-
- Medians: A 1×10 tensor where each field is the median value of the coin (average of lowest offer and highest bid) every 30 seconds for the past 5 minutes
- Offers/Bids: Each a 1×20 tensor. Coinbase provides a snapshot of active bids/offers along with changes to the order book. At every record bids/offers 2% below and above the median respectively are bucketized into 0.1% increments. The percentile of bid/offers in each bucket is calculated and normalized and used as input features
- Product ID: The model operates on 55 different coins. While different coins share different market properties they would each have unique characteristics of their own. The one hot vector would help the model learn unique characteristics of each coin.
-
- Labels
-
- 5 different labels are provided. Each label computes the profit of taking a particular action over the next 5 minutes. There are 5 actions to select from
- Force buy: Buy the best offer immediately
- Close Buy: Create a buy order right under the best offer
- Force Sell: Sell to the best bid immediately
- Close sell: Create a sell order right above the best bid
- No Op: Don’t create any buy/sell orders
- 5 different labels are provided. Each label computes the profit of taking a particular action over the next 5 minutes. There are 5 actions to select from
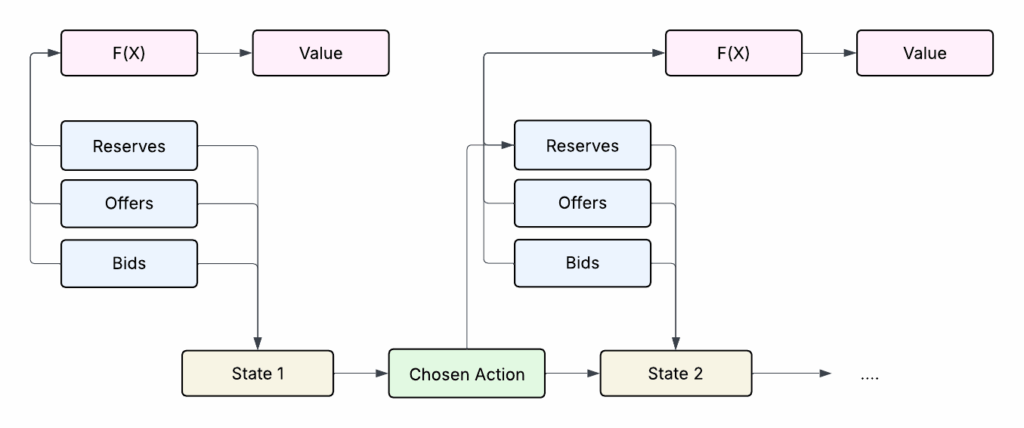
The approach for calculating the profits (or values) of each label is based on a breadth first graph search with pruning. The algorithm is set up to make a trade action every 4 seconds. The label value is calculated as the profit that can be acquired by taking the most optimal set of actions every 4 seconds for up to 5 minutes.
For each action there are 5 possible actions in the next 4 seconds. The space can grow exponentially so sub optimal selections are pruned in order to reduce the space.
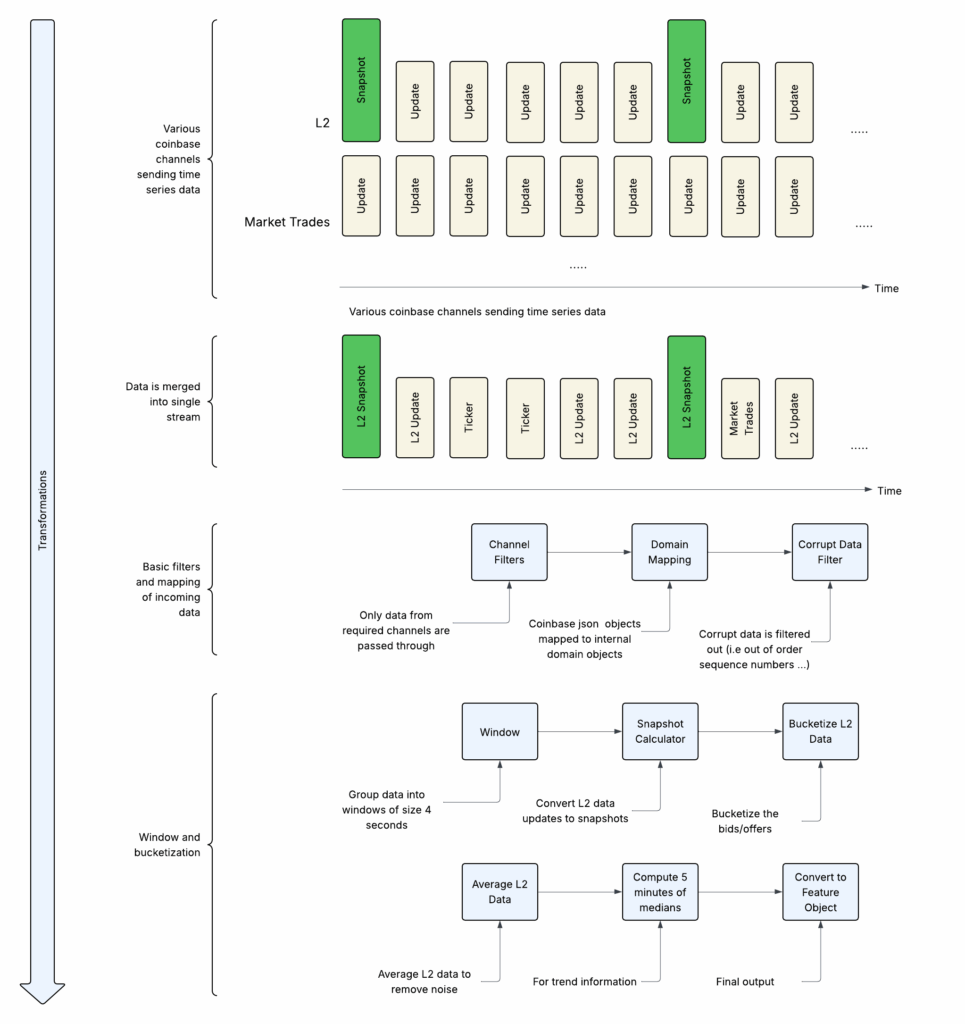
Data Pipelines
The data that arrives from Coinbase needs to be transformed before it can be used within the ML models.
-
- Data arrives in different channels which requires merging into a single record based on a common key (i.e timestamp)
- Channel Filters: Filter out data from channels we don’t need such as heartbeats, subscription notifications …
- Domain Mapping: The objects that arrive from coinbase have nested structures with information that was not needed as part of the features that were being built. This transformation would map the coinbase records to internal domain objects.
- Corrupt Data Filter: Due to the stateful nature of the mapping that was being done it was critical to ensure the data that were arriving had not been corrupted (i.e. such as repeated records). In case of corrupt data they would be filtered out at this stage.
- Window: Records would arrive from coinbase at different intervals, often multiple records a second. The goal was to build a trade algorithm that makes a decision every 4 seconds. Records were merged into a single record every 4 seconds.
-
- Snapshot Calculator: In order to maintain an order book of bids/offers we need to subscribe to the L2 channel from coinbase. Coinbase first sends a snapshot of all bids/offers and on all subsequent updates only sends the incremental changes. In order to maintain a complete orderbook state needs to be maintained in the data pipelines and updates merged with prior snapshots to generate new snapshots.
- Bucketized L2 Data: Bids/offers are bucketized as explained above in the features and labels section
- Average L2 Data: Due to sudden changes in bids/offers the values of 3 previous records are aggregated and averaged before being used in the feature using stateful time series map operations
- 5 Mins of Medians: The medians as explained in the features and labels section is computed using stateful time series map operations
- Feature Object: A final record is emitted which contains the models features and labels.
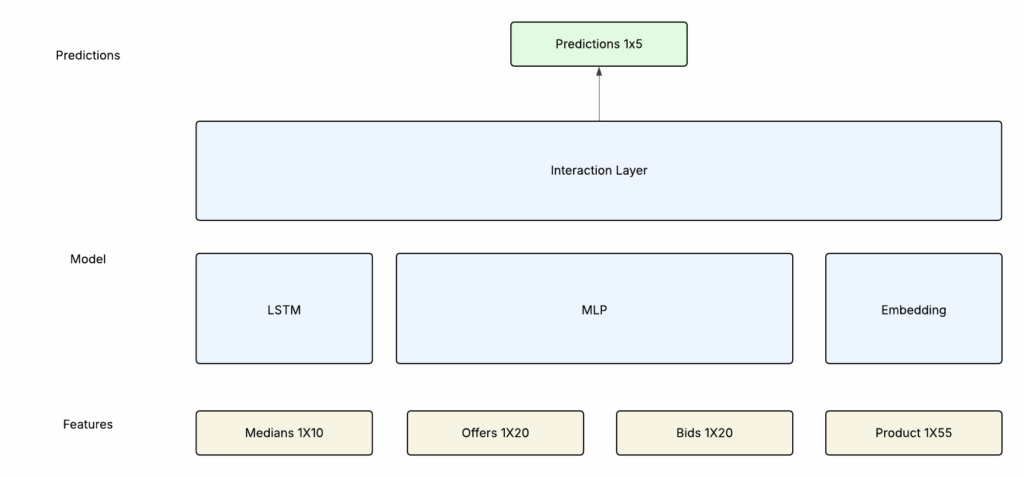
Model
The model consists of 4 different sections:
-
- LSTM: Takes input from the median tensor which contains time series data. The goal is to extract time series related patterns from this input
- MLP: A multi layer perceptron applied to the concatenation of the bids and offers.
- Embeddings: Applied to the one hot vector of the product id. Embeddings will help obtain similarities between the different coins.
- Interaction Layer: Another MLP applied to the outputs of the LSTM, Bid/Offers MLP and embeddings and is used to generate the output predictions
Various hyperparameter and variations of the model were explored in this process:
- Different number of layers for each tensor
- Different hidden size for each tensor
- Different loss function. MSE, BCE, … different loss functions also required changing the labels. For example in BCE instead of having the action value would need to replace with the a 1/0 label indicating if the action is optimal or not
- Various learning curve parameters and optimizers
- ….
Future Directions
While a profitable algorithm was not developed as part of this project however the following would be future directions to explore:
- Developing analytical tools to better understand the correlation between the input features and the output labels.
- Explore additional signals. The current feature relies exclusively on the historic prices of the coin itself. Signals from other coins or external sources (i.e new articles, tweets, …) could provide stronger correlation with the direction of the coins.
- Gain access to additional training data. The models were trained on about 100 days of data each feature 4 seconds apart that is about 2 million records which proved challenging to both train the model while avoiding overfitting problems
- Consider transformer architecture over LSTM
Description
Goals
Develop an e2e deep learning system for crypto trading:
- Operate across 55 different coins
- Data collection
- Offline and online feature generation for training and serving
- Design and implement a deep learning model for predicting optimal trade actions
- Developing simulation and other offline evaluation systems
- Coinbase integration for online trading execution
Note: A profitable algorithm was not developed however future directions and next steps are shared in the end.